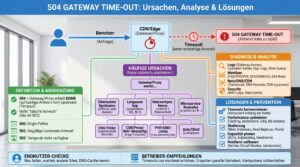
504 gateway time-out: Ursachen, Diagnose, Auswirkungen und Gegenmaßnahmen
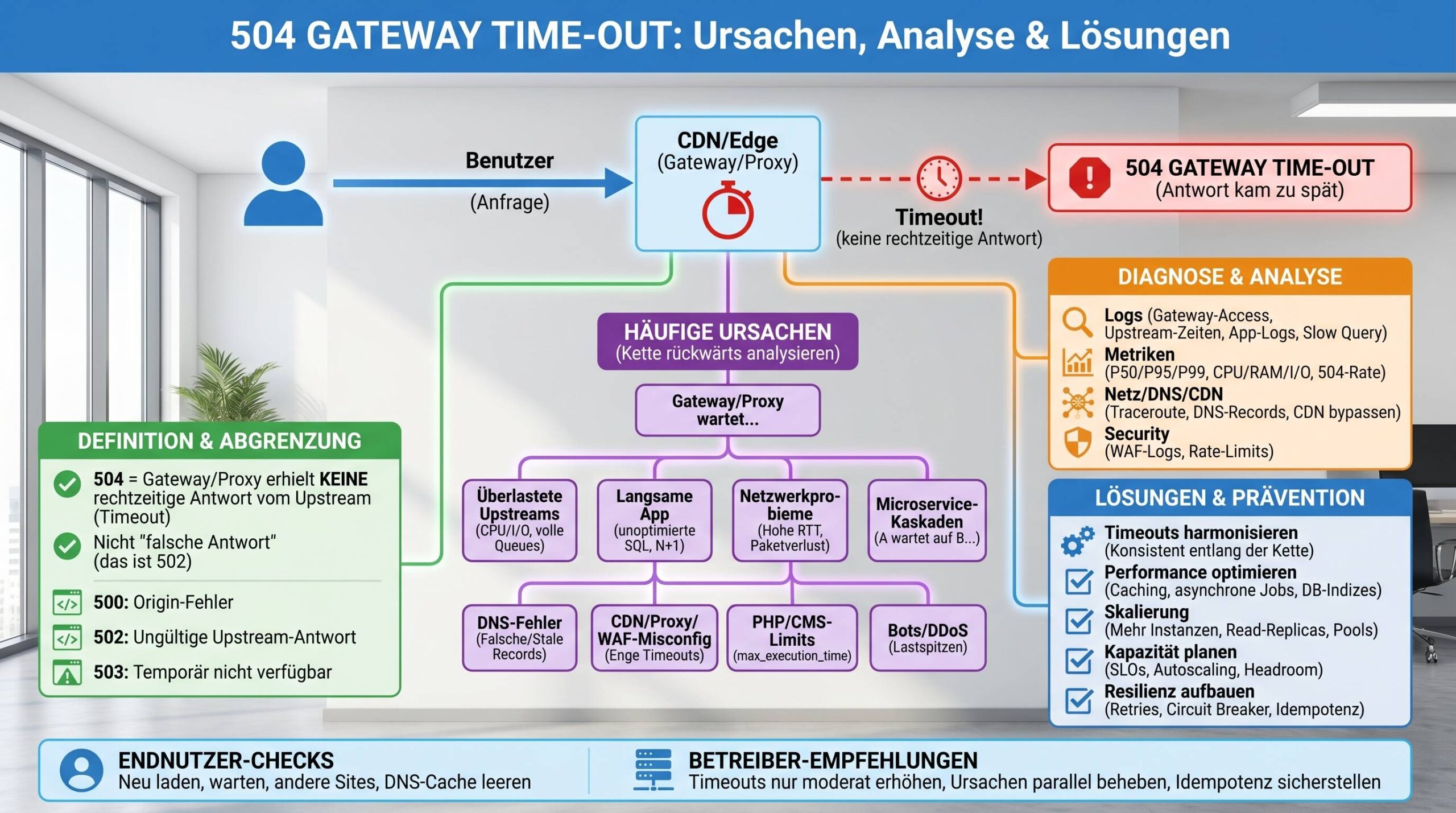
Der HTTP-Statuscode 504 signalisiert: Ein Server in der Rolle als Gateway oder Proxy hat nicht rechtzeitig eine Antwort von einem nachgelagerten (Upstream-)Server erhalten. Das kann ein Reverse-Proxy, Load-Balancer, CDN-Edge, API-Gateway oder eine andere Vermittlungskomponente sein. Kurz: Die Anfrage hing irgendwo zwischen Gateways und Backends fest, bis ein Timeout griff – und du siehst das Ergebnis als 504 gateway time-out im Browser oder im API-Client.
Wichtig ist die Abgrenzung: Ein 504 bedeutet nicht „falsche Antwort“ (das wäre 502), sondern „keine Antwort innerhalb der Frist“. Diese Feinheit entscheidet in der Praxis über Diagnoseweg und Fix.
Abgrenzung zu 500, 502 und 503 – schneller Überblick
| Code | Name | Wann einsetzen | Typischer Auslöser | Operator-Hinweis |
|---|---|---|---|---|
| 500 | Internal Server Error | Unerwarteter Fehler in der Anwendung/auf dem Origin | Exception, Crash, unhandled error | Applikationslogs prüfen, Fehlerbehandlung verbessern |
| 502 | Bad Gateway | Gateway erhielt ungültige oder unvollständige Antwort vom Upstream | Protokollfehler, TLS-Mismatch, kaputte Antwort | Handshake/Protokolle prüfen, Upstream-Fehlerbild eingrenzen |
| 503 | Service Unavailable | Temporäre Nichtverfügbarkeit (Wartung/Überlast) | Wartungsfenster, Ressourcengrenzen | Optional Retry-After setzen, Kapazität/Queues managen |
| 504 | Gateway Timeout | Gateway erhielt keine rechtzeitige Antwort vom Upstream | Lange Laufzeiten, Netzwerk-Latenz, DNS/CDN/WAF-Probleme | Timeouts, Latenzen, Upstream-Health prüfen, Kettenanalyse |

Wie es zu einem 504 kommt – der typische Ablauf in verteilten Systemen
In modernen Setups trifft deine Anfrage selten direkt den Applikationsserver. Stattdessen laufen Requests über ein oder mehrere Gateways (z. B. CDN → Reverse-Proxy → API-Gateway → Microservice). Jede Stufe besitzt eigene Zeitlimits. Wird ein Limit überschritten, bricht die entsprechende Stufe ab und liefert 504.
Client
│
▼
CDN/Edge (Gateway, Timeout A)
│
▼
Reverse-Proxy / Load Balancer (Timeout B)
│
▼
App-Server / PHP-FPM / Node / JVM (Execution Timeout)
│
▼
Datenbank / externer API-Dienst (Query / Network Timeout)
Merke: 504 entsteht an der Stelle, die wartet – nicht zwingend dort, wo die eigentliche Ursache liegt. Diagnose heißt deshalb: Kette rückwärts verfolgen.
Häufige Ursachen – vom DNS bis zur Datenbank
- Überlastete Upstreams: Zu wenig Worker/Threads, volle Queues, hoher CPU-/I/O-Load. Besonders kritisch bei synchronen, komplexen Requests (z. B. Checkout, Reporting).
- Langsame/ineffiziente Anwendung: Unoptimierte SQL-Abfragen, fehlende Indizes, N+1-Queries, große Aggregationen, blockierende externe API-Calls.
- Netzwerkprobleme: Hohe RTT, Paketverlust, instabile Routen, Cross-AZ/Region-Latenz, kaputte Verbindungen in VPN/Hybrid-Topologien.
- DNS-Fehler: Falsche/alte A/AAAA-Records, unvollständige Zonen, langsame Resolver, stale Caches, Migrationsartefakte.
- CDN/Proxy/WAF-Misconfig: Zu enge Timeout-Defaults, geblockte IPs, Header/Body-Limits, fehlerhafte Origin-Konfiguration.
- PHP-/CMS-Probleme: Überschrittene max_execution_time, zu kleine request_terminate_timeout, speicherhungrige Plugins, langlaufende Scripte in WordPress/Shopware/PrestaShop.
- Microservices & Kaskaden: Service A wartet auf B, B auf C – und irgendwo klemmt es. Ergebnis: Timeouts am Rand (Gateway) statt klare Fehlermeldung aus der Tiefe.
- Bots/DDoS/Scraper: Aggressive Lastspitzen, fehlende Rate-Limits, Ressourcenerschöpfung – echte Benutzer sehen 504.
Endnutzer-Symptome und schnelle Selbsttests
Auch wenn 504 serverseitig ist, kannst du als Nutzer ein paar Dinge prüfen, um lokale Ursachen auszuschließen:
- Seite neu laden, ein paar Sekunden warten.
- Andere Websites testen – ist nur eine Domain betroffen, liegt es wahrscheinlich dort.
- Router/Modem neu starten, Proxy-/VPN-Einstellungen checken.
- DNS-Cache leeren oder auf öffentlichen DNS umschalten.
- Anderen Browser/Inkognito-Modus probieren.

Serverseitige Diagnose: strukturiert statt Rätselraten
1) Logs korrelieren (Gateway ↔ Upstream)
- Access-/Error-Logs des Gateways (NGINX/Apache/CDN) auf 504-Einträge und Upstream-Zeiten (upstream_response_time) prüfen.
- Applikations-Logs im Zeitraum der 504-Events gegenprüfen (Langläufer, Exceptions, GC-Pausen, DB-Timeouts).
- Datenbank-Logs (slow query log) sowie externe API-Logs betrachten.
2) Metriken und Verläufe
- Latenz-Perzentile (P50/P95/P99) je Endpoint – steigen Outliers an?
- Ressourcen (CPU, RAM, I/O, Sockets, Verbindungen, Queue-Lengths).
- Netzwerk (RTT, Paketverlust, TLS-Handshakes, Retransmissions).
- Error-Rates speziell nach Statuscode 504 filtern und alarmieren.
3) Netzwerk/DNS/CDN
- Traceroute/MTR zwischen Gateway und Upstream fahren, AZ/Region/Peering prüfen.
- DNS-Records validieren, TTLs und Propagation kontrollieren.
- CDN temporär umgehen (Hosts-Datei) oder pausen, um Origin direkt zu testen.
4) Security-Schicht
- WAF-/Firewall-Logs auf False Positives prüfen (geblockte CDNs, API-IPs, ASNs).
- Rate-Limits/Bot-Filter justieren, wenn legitimer Traffic limitiert wird.
NGINX, Apache, PHP-FPM & Co.: Timeouts sinnvoll konfigurieren
Timeouts sind Sicherheitsgurte – sie sollen echte Hänger erkennen, aber nicht legitime Langläufer zerreißen. Passe sie an deine Workloads an und halte die Kette konsistent.
NGINX (Reverse-Proxy/FastCGI)
# Für Upstream-HTTP (proxy_*)
proxy_connect_timeout 10s;
proxy_send_timeout 75s;
proxy_read_timeout 75s;
send_timeout 75s;
# Für PHP-FPM (FastCGI)
fastcgi_connect_timeout 10s;
fastcgi_send_timeout 75s;
fastcgi_read_timeout 75s;
- Richtwert: Setze Read-Timeouts so, dass typische Business-Operationen (z. B. Checkout) Luft haben, aber Deadlocks nicht kaschiert werden.
- Achtung: Ein „einfach nur hochdrehen“ ist kurzfristig hilfreich, langfristig riskant. Ursache beheben bleibt Pflicht.
Apache (mod_proxy, mod_fcgid)
# Global
Timeout 120
# Für Proxied Backends
ProxyTimeout 120
PHP-FPM / PHP
; php.ini
max_execution_time = 60 ; je nach Workload 60–120s
memory_limit = 512M ; vermeiden von OOM/Abbrüchen
; PHP-FPM Pool (www.conf)
request_terminate_timeout = 90s
pm.max_children = 20 ; passend zur CPU/Datenbankgröße
Stimme fastcgi_read_timeout (NGINX), max_execution_time (PHP) und request_terminate_timeout (FPM) aufeinander ab. Verhindere, dass FPM noch arbeitet, während das Gateway längst abgebrochen hat – sonst riskierst du inkonsistente Nebenwirkungen.
Weitere Stacks (Beispiele)
- Node.js: Prüfe
server.headersTimeoutundserver.requestTimeoutsowie Upstream-Client-Timeouts (Axios/fetch). - Java/Servlet: Connector-connectionTimeout (Tomcat/Undertow/Jetty) und Threadpools dimensionieren.
- Go:
http.Client{ Timeout: ... }für Outbound,ReadHeaderTimeout/IdleTimeoutfür Inbound setzen.
Tabelle: typische Default-/Richtwerte
| Komponente | Parameter | Default (häufig) | Pragmatischer Bereich | Hinweis |
|---|---|---|---|---|
| NGINX | proxy_read_timeout | 60s | 60–180s | Längere Backends tolerieren, aber nicht verstecken |
| NGINX | fastcgi_read_timeout | 60s | 60–180s | Abgleich mit PHP-Zeiten nötig |
| Apache | Timeout / ProxyTimeout | 60s | 60–180s | Vorsicht bei Keep-Alive-Last |
| PHP | max_execution_time | 30s | 60–120s | Nur wo nötig erhöhen, Queries optimieren |
| PHP-FPM | request_terminate_timeout | 0 (unbegrenzt) | 60–180s | Hänger vermeiden, Logging bei Terminierung aktivieren |
Performance-Optimierung: Ursachen abstellen statt Symptome dämpfen
Datenbank
- Slow-Query-Log auswerten, Indizes gezielt ergänzen/korrigieren.
- Abfragen vereinfachen, JOINS und Aggregationen optimieren, N+1 vermeiden.
- Lange Transaktionen und Sperrkonflikte reduzieren, Batchgrößen begrenzen.
Applikation
- Profiling für Hotpaths (CPU/Wall-Time/Allocations).
- Async-Modelle: Lange Jobs entkoppeln (Queue/Worker), HTTP nicht blockieren.
- Caching auf mehreren Ebenen: App-, Proxy- und CDN-Cache mit Cache-Control, ETag, Last-Modified.
- Antwortgrößen und Serialisierung optimieren (kompakt, gzip/br, Pagination).
Skalierung, Lastverteilung und SLOs
- Horizontal skalieren: Mehr App-Instanzen hinter L7-Load-Balancer, Sticky-Sessions vermeiden, wenn nicht nötig.
- Datenbank-Skalierung: Read-Replicas, Sharding, Caching-Layer (z. B. Redis), Connection-Pools korrekt konfigurieren.
- Kapazitätsplanung: Trends, Peak-Faktoren, Headroom definieren; Autoscaling mit sinnvollen Cooldowns.
- SLOs formulieren (z. B. „P95 < 300 ms“, „5xx < 0,5%“), Alarme anhand Perzentilen statt nur Mittelwerten.
Wichtige Metriken (Beispiele)
| Kategorie | Metrik | Signal bei 504-Risiko | Aktion |
|---|---|---|---|
| Latenz | P95/P99 Response Time | Sprunghafte Outliers | Hotpaths optimieren, Timeouts prüfen |
| Fehler | Rate 5xx (504 separat) | Anstieg korreliert mit Peak-Traffic | Skalieren, Rate-Limits, Backpressure |
| Ressourcen | CPU, RAM, I/O-Queue | Nahe 100% / tiefe Queues | Vertikal/horizontal skalieren |
| Netz | RTT, Retransmits, TLS Handshakes | Erhöht/instabil | Peering prüfen, AZ/Region nähern |
CDN, WAF und Firewall: Freund oder Flaschenhals
- CDN: Entkoppel L7-Caching von Origin; bei 504 testen: CDN pausieren oder Origin direkt ansteuern.
- WAF: Regeln/Anomalie-Scores feinjustieren; legitime Backends/CDN-IP-Ranges whitelisten.
- Firewall/NAT: Session-Timeouts, Connection-Tracking, Port-Exhaustion überwachen.
APIs, Microservices und Resilienz-Patterns
In service-orientierten Landschaften sind Retries, Exponential Backoff, Jitter und Circuit Breaker Pflicht, um 504 gateway time-out-Ereignisse abzufangen, ohne Systeme zusätzlich zu fluten.
Beispiel: Retry mit Exponential Backoff + Jitter (Pseudocode)
maxAttempts = 5
baseDelay = 200ms
for attempt in 1..maxAttempts:
resp = call()
if resp.ok:
return resp
if resp.status in [504, 503, 429, 408]:
delay = baseDelay * 2^(attempt-1)
delay += random(0, 100ms) # Jitter
sleep(delay)
else:
break
raise Error("Request failed")
- Circuit Breaker: Nach X Fehlversuchen „offen“ schalten, kurze Pause, dann half-open mit Probe-Requests.
- Async-Modelle: Lange Operationen als Job starten, Status/Ergebnis per Polling/Webhook abholen statt HTTP-Request offen zu halten.
Scraping und Bots – wenn „gut gemeint“ 504 triggert
- Als Scraper: Request-Rate drosseln, nur nötige Ressourcen anfragen, Backoff bei 504 implementieren, Sessions wiederverwenden, Caching nutzen.
- Als Betreiber: Rate-Limits, Bot-Management, Captchas und Hints (Robots, dedizierte APIs) anbieten; Missbrauch eindämmen, legitime Integrationen ermöglichen.
SEO- und Business-Auswirkungen
- User Experience: Timeouts frustrieren, Conversion sinkt, Support-Anfragen steigen.
- SEO: Häufige/längere 5xx-Phasen können Rankings schädigen und Re-Crawls verzögern. Uptime-Monitoring und 5xx-Alerting sind Pflicht.
- APIs/Prozesse: 504 in B2B-Integrationen erzeugt Retries, Latenz und potenziell doppelte/teilverarbeitete Transaktionen – Idempotenz und Job-Design beachten.
Pragmatische Checklisten
Schnelle Triage (15–30 Minuten)
- Dashboard: 5xx-Rate (504 isoliert), P95/P99-Latenz, CPU/RAM/DB-Connections checken.
- NGINX/Apache-Logs: betroffene Pfade, upstream_response_time, beteiligte Upstreams.
- CDN-Status/Origin-Health und DNS-Records validieren.
- Traffic-Spitzen/Bot-Anomalien: Top-IP/UA, RPS-Sprünge, Hot-Endpoints.
- Hotfix: Falls produktkritisch – Timeouts moderat erhöhen, vertikal skalieren, Rate-Limit temporär anpassen.
Deep Dive (4–48 Stunden)
- Langläufer-Analyse: Trace-/Profiling, slow queries, Heap-/GC-Inspektion, Lock-Contention.
- Architektur: Sync-Abhängigkeiten, Kaskaden-Timeouts, Queue/Backpressure einziehen.
- Konfiguration: Timeouts entlang der Kette harmonisieren; Read/Connect/Execution klar definieren.
- Netzwerk: MTR/Traceroutes, Peering/Regionen, Paketverlust; ggf. Dienst nahe an Daten bewegen.
- Security: WAF-False-Positives, Firewall-Sessions, NAT-Port-Exhaustion ausschließen.
- Tests: Last-/Chaos-Tests mit realistischen Datensätzen und Denkpausen (Think Time).
Häufige Stolperfallen – kurz und knapp
- Nur Timeouts erhöhen statt Ursachen zu beheben – kaschiert Probleme, verbessert sie nicht.
- Inkonstistente Timeout-Kette (Gateway 60s, App 120s, DB 30s) – führt zu Race Conditions und Geisterprozessen.
- Fehlende Idempotenz – Retries erzeugen doppelte Buchungen/Jobs.
- Kein Outlier-Fokus – Durchschnittszeiten sind okay, aber P99 reißt dir das SLO.
- CDN-/WAF-Fehldiagnose – Problem am falschen Ort gesucht, weil die Kette nicht isoliert wurde.
Fazit
Ein 504 gateway time-out ist kein einzelner Serverfehler, sondern ein Symptom einer zeitlich aus dem Takt geratenen Kommunikationskette. Du behebst ihn nachhaltig, wenn du drei Ebenen zusammendenkst: 1) Beobachtbarkeit (Logs, Metriken, Traces) zur schnellen Eingrenzung, 2) Konfiguration (konsistente Timeouts, saubere Gateway-/WAF-/CDN-Settings) und 3) Performance & Resilienz (Query-/Code-Optimierung, Caching, Skalierung, Retries, Circuit Breaker, Async-Design). Kurzfristig darfst du Timeouts erhöhen und Ressourcen skalieren, mittel- und langfristig musst du Hotpaths entschärfen, Abhängigkeiten entkoppeln und eine robuste Architektur etablieren. So reduzierst du nicht nur die Häufigkeit von 504-Fehlern, sondern hebst die Verlässlichkeit deiner gesamten Plattform – für Nutzer, Crawler und geschäftskritische Prozesse gleichermaßen.
FAQ
Was ist der Unterschied zwischen 502 und 504?
502 bedeutet: Das Gateway hat eine Antwort bekommen, aber sie war ungültig/kaputt. 504 bedeutet: Das Gateway hat gar keine rechtzeitige Antwort bekommen – die Frist ist abgelaufen.
Wann sollte ich Timeouts erhöhen – und wie viel?
Erhöhe Timeouts, wenn legitime, bekannte Langläufer (z. B. Reports, Exporte) regelmäßig an die Grenze stoßen. Arbeite in moderaten Schritten (z. B. von 60s auf 90–120s) und beobachte Latenz-Perzentile. Parallel Ursachen (Queries, Code, Architektur) optimieren.
Kann ein DNS-Problem wirklich 504 auslösen?
Ja. Wenn Gateways falsche oder veraltete Zieladressen verwenden oder Resolver langsam reagieren, wartet das Gateway auf eine Antwort, die nie kommt – Ergebnis: 504.
Wie erkenne ich, ob mein CDN oder mein Origin schuld ist?
Umschiffe das CDN temporär (Hosts-Datei oder „Pause“-Funktion des Anbieters). Tritt das Problem direkt am Origin auf, liegt es dort. Verschwindet es, ist das CDN oder dessen Konfiguration zu prüfen.
Was kann ich als Endnutzer bei 504 tun?
Seite neu laden, kurz warten, anderen Browser testen, Router/Modem neu starten, DNS-Cache leeren oder DNS wechseln. Ist nur eine Website betroffen, liegt die Ursache meist dort – abwarten oder Support kontaktieren.
Wie verhindere ich, dass Retries alles schlimmer machen?
Implementiere begrenzte Retries mit Exponential Backoff und Jitter, nutze Circuit Breaker, setze Idempotency-Keys für kritische Vorgänge und beobachte die Lastwirkungen im Monitoring.
Hilft Caching gegen 504?
Ja. Gut gesetzte Caches (App, Proxy, CDN) entlasten Backends und glätten Peaks. Achte auf korrekte Cache-Control-, ETag– und Last-Modified-Header sowie sinnvolle Invalidation.
Warum sehe ich 504 nur bei bestimmten API-Endpunkten?
Häufig sind einzelne Pfade Hotspots mit komplexen Logik-/DB-Pfaden oder externen Abhängigkeiten. Analysiere Latenz-Perzentile per Endpoint, profiliere die betroffenen Routen und optimiere gezielt.
Kann eine WAF 504 erzeugen?
Indirekt ja. Blockiert oder verzögert die WAF legitime Verbindungen (False Positives, Rate-Limits), sieht das Gateway keine rechtzeitige Antwort. Prüfe WAF-Logs/Regeln und whiteliste vertrauenswürdige Upstreams/CDN-Ranges.
Was ist die nachhaltigste Maßnahme gegen 504?
Ursachenbeseitigung: Datenbank- und Code-Optimierung, asynchrones Design langer Jobs, saubere Timeouts entlang der Kette, Caching, Lastverteilung und Resilienz-Patterns (Retries, Circuit Breaker). Monitoring und klare SLOs sorgen dafür, dass Probleme früh sichtbar werden.